Data management and analytics have become crucial components of modern businesses, with organizations relying on vast amounts of data to inform their decisions. Two concepts that have gained significant attention in recent years are Data Lake and Delta Lake, each offering a unique approach to storing, managing, and analyzing data. In this article, we will delve into the details of both Data Lake and Delta Lake, comparing their architectures, benefits, and use cases to help organizations make informed decisions about their data management strategies.
Key Points
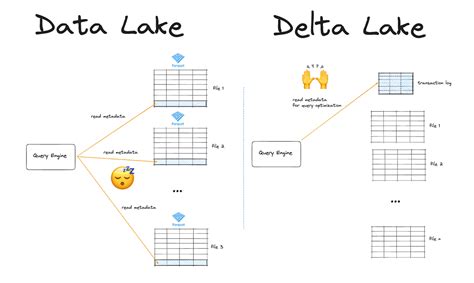
- Data Lake is a centralized repository that stores raw, unprocessed data in its native format, allowing for flexibility and scalability.
- Delta Lake is an open-source storage layer that provides a transactional framework for data lakes, enabling ACID transactions and improving data reliability.
- Data Lake focuses on data ingestion and storage, whereas Delta Lake emphasizes data processing, reliability, and performance.
- Both Data Lake and Delta Lake support various data formats and are designed to work with big data analytics tools.
- The choice between Data Lake and Delta Lake depends on the organization's specific needs, with Data Lake suitable for raw data storage and Delta Lake ideal for processed data and high-performance analytics.
Data Lake Architecture and Benefits

A Data Lake is a centralized repository that stores raw, unprocessed data in its native format, allowing for flexibility and scalability. This approach enables organizations to store large amounts of data from various sources, including social media, IoT devices, and sensors, without having to worry about the data’s structure or schema. The Data Lake architecture is designed to handle the volume, velocity, and variety of big data, making it an attractive option for organizations dealing with large datasets.
The benefits of using a Data Lake include:
- Flexibility: Data Lake stores data in its native format, allowing for easy integration with various data sources and tools.
- Scalability: Data Lake can handle large amounts of data, making it suitable for big data analytics and machine learning applications.
- Cost-effectiveness: Data Lake eliminates the need for expensive data warehousing and ETL (Extract, Transform, Load) processes.
Data Lake Use Cases
Data Lake is suitable for various use cases, including:
- Data warehousing: Data Lake can be used as a data warehouse, providing a centralized repository for storing and analyzing data.
- Big data analytics: Data Lake is designed to handle large datasets, making it an ideal choice for big data analytics and machine learning applications.
- IoT data management: Data Lake can store and process large amounts of IoT data, enabling organizations to gain insights into their IoT devices and sensors.
Delta Lake Architecture and Benefits

Delta Lake is an open-source storage layer that provides a transactional framework for data lakes, enabling ACID (Atomicity, Consistency, Isolation, Durability) transactions and improving data reliability. Delta Lake is designed to work with existing data lakes, providing a layer of abstraction and enabling organizations to build reliable and high-performance data pipelines.
The benefits of using Delta Lake include:
- Reliability: Delta Lake provides ACID transactions, ensuring that data is processed reliably and consistently.
- Performance: Delta Lake is optimized for high-performance data processing, making it suitable for real-time analytics and machine learning applications.
- Scalability: Delta Lake is designed to scale with large datasets, making it an ideal choice for big data analytics and data science applications.
Delta Lake Use Cases
Delta Lake is suitable for various use cases, including:
- Real-time analytics: Delta Lake provides high-performance data processing, making it an ideal choice for real-time analytics and machine learning applications.
- Data science: Delta Lake is designed to work with existing data lakes, providing a reliable and high-performance storage layer for data science applications.
- Machine learning: Delta Lake provides a scalable and reliable storage layer for machine learning models, enabling organizations to build and deploy models quickly and efficiently.
| Category | Data Lake | Delta Lake |
|---|---|---|
| Architecture | Centralized repository for raw data | Transactional framework for data lakes |
| Benefits | Flexibility, scalability, cost-effectiveness | Reliability, performance, scalability |
| Use Cases | Data warehousing, big data analytics, IoT data management | Real-time analytics, data science, machine learning |

In conclusion, Data Lake and Delta Lake are two distinct approaches to data management, each with its own strengths and weaknesses. By understanding the benefits and use cases of each approach, organizations can make informed decisions about their data management strategies and build a robust and scalable data infrastructure that meets their unique needs.
What is the primary difference between Data Lake and Delta Lake?
+The primary difference between Data Lake and Delta Lake is their approach to data management. Data Lake is a centralized repository for raw data, while Delta Lake is a transactional framework for data lakes that provides ACID transactions and improves data reliability.
What are the benefits of using Data Lake?
+The benefits of using Data Lake include flexibility, scalability, and cost-effectiveness. Data Lake stores data in its native format, allowing for easy integration with various data sources and tools, and can handle large amounts of data, making it suitable for big data analytics and machine learning applications.
What are the benefits of using Delta Lake?
+The benefits of using Delta Lake include reliability, performance, and scalability. Delta Lake provides ACID transactions, ensuring that data is processed reliably and consistently, and is optimized for high-performance data processing, making it suitable for real-time analytics and machine learning applications.