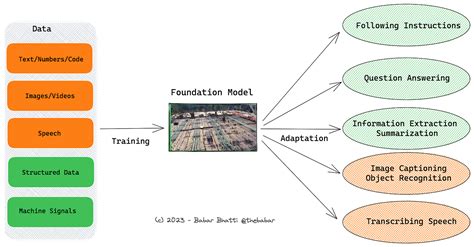
The field of artificial intelligence (AI) has witnessed significant advancements in recent years, with the development of various models designed to process and generate human-like language. Two prominent types of models that have gained considerable attention are Foundation Models and Large Language Models (LLMs). While both models share some similarities, they differ in their underlying architecture, training objectives, and applications. In this article, we will delve into the world of Foundation Models and LLMs, exploring their strengths, weaknesses, and potential use cases.
Key Points
- Foundation Models are designed to learn generalizable features from large datasets, enabling them to perform well on a wide range of tasks.
- LLMs are specifically trained on vast amounts of text data, focusing on generating coherent and contextually relevant language.
- Foundation Models can be fine-tuned for specific tasks, whereas LLMs are often used as-is for language generation and conversation.
- Both models have shown impressive results in various applications, including natural language processing, computer vision, and speech recognition.
- The choice between Foundation Models and LLMs depends on the specific use case, dataset, and desired outcome.
Foundation Models: A General-Purpose Approach

Foundation Models are designed to learn generalizable features from large datasets, which can be applied to a wide range of tasks. These models typically employ a multi-task learning approach, where they are trained on multiple tasks simultaneously, enabling them to develop a deep understanding of the underlying data distribution. Foundation Models can be thought of as a “Swiss Army knife” for AI, as they can be fine-tuned for specific tasks, such as image classification, object detection, or language translation.
One of the key advantages of Foundation Models is their ability to learn transferable features, which can be applied to new, unseen tasks. This property is particularly useful in situations where labeled data is scarce or expensive to obtain. By leveraging pre-trained Foundation Models, developers can adapt them to their specific use case, reducing the need for extensive training data and computational resources.
Architecture and Training Objectives
Foundation Models typically employ a modular architecture, consisting of multiple layers, each designed to capture different aspects of the data. The training objective of Foundation Models is often a combination of multiple loss functions, each corresponding to a specific task or modality. This multi-task learning approach enables the model to develop a rich representation of the data, which can be fine-tuned for specific tasks.
Some notable examples of Foundation Models include BERT (Bidirectional Encoder Representations from Transformers) and RoBERTa (Robustly optimized BERT approach). These models have achieved state-of-the-art results in various natural language processing tasks, such as question answering, sentiment analysis, and language translation.
Large Language Models (LLMs): A Specialized Approach

LLMs, on the other hand, are specifically designed to process and generate human-like language. These models are trained on vast amounts of text data, often using a combination of supervised and unsupervised learning techniques. LLMs are typically employed for language generation, conversation, and text classification tasks, where the goal is to produce coherent and contextually relevant language.
One of the key advantages of LLMs is their ability to capture long-range dependencies and nuances in language, enabling them to generate text that is often indistinguishable from human-written content. LLMs have been used in a variety of applications, including chatbots, virtual assistants, and content generation platforms.
Architecture and Training Objectives
LLMs typically employ a transformer-based architecture, which is well-suited for sequential data such as text. The training objective of LLMs is often a combination of masked language modeling and next sentence prediction, where the model is trained to predict missing words or sentences in a given text.
Some notable examples of LLMs include the Transformer-XL and the recent introduction of the "Conversational AI" model, which achieved state-of-the-art results in various language generation and conversation tasks.
| Model Type | Training Objective | Applications |
|---|---|---|
| Foundation Models | Multi-task learning | Natural language processing, computer vision, speech recognition |
| LLMs | Masked language modeling, next sentence prediction | Language generation, conversation, text classification |

Comparison and Future Directions
Both Foundation Models and LLMs have their strengths and weaknesses, and the choice between them ultimately depends on the specific use case and desired outcome. Foundation Models offer a general-purpose approach, enabling them to be fine-tuned for a wide range of tasks, whereas LLMs are specifically designed for language generation and conversation.
As the field of AI continues to evolve, we can expect to see further advancements in both Foundation Models and LLMs. One potential direction is the integration of these two approaches, where Foundation Models are used as a starting point for LLMs, enabling them to leverage the generalizable features learned by the Foundation Model.
Another area of research is the development of more efficient and scalable training methods, which can enable the training of even larger and more complex models. This could potentially lead to breakthroughs in areas such as natural language understanding, common sense reasoning, and human-AI collaboration.
What is the main difference between Foundation Models and LLMs?
+The main difference between Foundation Models and LLMs is their training objective and architecture. Foundation Models are designed to learn generalizable features from large datasets, whereas LLMs are specifically trained on vast amounts of text data for language generation and conversation.
Can Foundation Models be used for language generation tasks?
+Yes, Foundation Models can be fine-tuned for language generation tasks, but they may not perform as well as LLMs, which are specifically designed for this task. However, Foundation Models can be used as a starting point for LLMs, enabling them to leverage the generalizable features learned by the Foundation Model.
What are some potential applications of Foundation Models and LLMs?
+Some potential applications of Foundation Models and LLMs include natural language processing, computer vision, speech recognition, language generation, conversation, and text classification. These models can be used in a variety of industries, such as healthcare, finance, and education, to name a few.
Meta description suggestion: “Discover the differences between Foundation Models and Large Language Models (LLMs), and learn how to choose the right approach for your AI-powered project.” (140-155 characters)