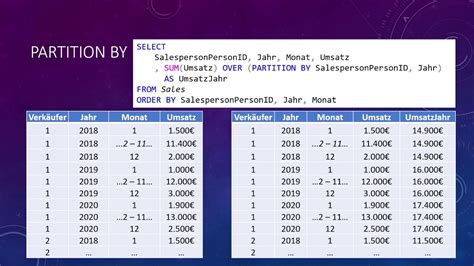
Partitioning data is a crucial step in data analysis and management, as it enables efficient data retrieval, improved query performance, and better data organization. In various fields, including data science, business intelligence, and database management, data partitioning plays a vital role in optimizing data storage and processing. This article will delve into the concept of data partitioning, its benefits, and explore five ways to partition data, including their applications, advantages, and potential limitations.
Key Points
- Data partitioning improves query performance and reduces data retrieval time
- Range-based partitioning is suitable for data with a continuous range of values
- List-based partitioning is ideal for data with a predefined list of values
- Hash-based partitioning is suitable for large datasets with random data distribution
- Composite partitioning combines multiple partitioning methods for optimal results
Understanding Data Partitioning

Data partitioning involves dividing a large dataset into smaller, more manageable pieces, called partitions, based on a specific criteria or key. This process enables faster data retrieval, improved query performance, and more efficient data management. By partitioning data, organizations can reduce storage costs, enhance data security, and improve overall data analysis and decision-making capabilities.
Benefits of Data Partitioning
The benefits of data partitioning are numerous, including improved query performance, reduced data retrieval time, and enhanced data security. By partitioning data, organizations can also reduce storage costs, improve data management, and enable more efficient data analysis and decision-making. Additionally, data partitioning enables better data organization, making it easier to manage and maintain large datasets.
5 Ways to Partition Data

There are several ways to partition data, each with its advantages and limitations. The following sections will explore five common methods of data partitioning, including range-based, list-based, hash-based, composite, and interval-based partitioning.
1. Range-Based Partitioning
Range-based partitioning involves dividing data into partitions based on a continuous range of values. This method is suitable for data with a continuous range of values, such as dates, temperatures, or ages. For example, a dataset containing customer information can be partitioned based on age ranges, such as 18-24, 25-34, and 35-44.
| Partition Method | Description |
|---|---|
| Range-Based | Divide data into partitions based on a continuous range of values |
| List-Based | Divide data into partitions based on a predefined list of values |
| Hash-Based | Divide data into partitions based on a hash function |

2. List-Based Partitioning
List-based partitioning involves dividing data into partitions based on a predefined list of values. This method is ideal for data with a predefined list of values, such as countries, states, or cities. For example, a dataset containing customer information can be partitioned based on a list of countries, such as USA, Canada, and Mexico.
3. Hash-Based Partitioning
Hash-based partitioning involves dividing data into partitions based on a hash function. This method is suitable for large datasets with random data distribution, such as transactional data or log files. Hash-based partitioning ensures that data is evenly distributed across partitions, enabling efficient data retrieval and query performance.
4. Composite Partitioning
Composite partitioning involves combining multiple partitioning methods to achieve optimal results. This method enables organizations to partition data based on multiple criteria, such as range, list, and hash. For example, a dataset containing customer information can be partitioned based on age ranges and countries, enabling efficient data retrieval and analysis.
5. Interval-Based Partitioning
Interval-based partitioning involves dividing data into partitions based on fixed intervals, such as daily, weekly, or monthly. This method is suitable for time-series data, such as sales data or website traffic. Interval-based partitioning enables efficient data retrieval and analysis, making it ideal for applications that require frequent data updates and analysis.
What is data partitioning, and why is it important?
+Data partitioning is the process of dividing a large dataset into smaller, more manageable pieces, called partitions, based on a specific criteria or key. Data partitioning is important because it enables efficient data retrieval, improves query performance, and reduces data retrieval time.
What are the benefits of range-based partitioning?
+Range-based partitioning enables efficient data retrieval and query performance, reduces data retrieval time, and improves data security. It is suitable for data with a continuous range of values, such as dates, temperatures, or ages.
How does hash-based partitioning work?
+Hash-based partitioning involves dividing data into partitions based on a hash function. The hash function ensures that data is evenly distributed across partitions, enabling efficient data retrieval and query performance.
In conclusion, data partitioning is a crucial step in data analysis and management, enabling efficient data retrieval, improved query performance, and better data organization. By understanding the different methods of data partitioning, organizations can optimize their data storage and processing, improve data security, and enable more efficient data analysis and decision-making. Whether using range-based, list-based, hash-based, composite, or interval-based partitioning, the key is to choose the method that best suits the specific needs and requirements of the organization.
