Partitioning data by row number is a common requirement in various data processing and analysis tasks. This can be particularly useful when dealing with large datasets where dividing the data into manageable chunks is necessary for efficient processing or analysis. In this article, we will explore the concept of row number partitioning, its applications, and how it can be implemented in different database management systems and programming languages.
Understanding Row Number Partitioning

Row number partitioning involves dividing a dataset into partitions based on the row number of each record. This can be done in various ways, including sequential partitioning, where each partition contains a consecutive range of row numbers, or random partitioning, where row numbers are randomly assigned to partitions. The choice of partitioning strategy depends on the specific requirements of the application or analysis being performed.
Applications of Row Number Partitioning
Row number partitioning has several applications in data processing and analysis. One common use case is in data sampling, where a random sample of rows is selected from a larger dataset for analysis. By partitioning the data by row number, it becomes easier to select a representative sample. Another application is in parallel processing, where large datasets are divided into smaller partitions that can be processed concurrently, improving overall processing efficiency.
| Partitioning Strategy | Description |
|---|---|
| Sequential Partitioning | Divide data into consecutive ranges of row numbers |
| Random Partitioning | Randomly assign row numbers to partitions |
| Hash Partitioning | Distribute rows across partitions based on a hash function |

Implementing Row Number Partitioning

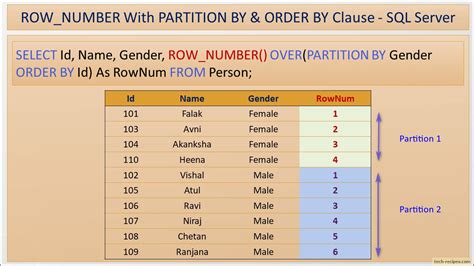
The implementation of row number partitioning can vary significantly depending on the database management system or programming language being used. For example, in SQL, the ROW_NUMBER() function can be used to assign a unique row number to each row within a result set, which can then be used to partition the data. In programming languages like Python, libraries such as Pandas provide efficient methods for partitioning dataframes based on row numbers.
Example in SQL
In SQL, you can use the ROW_NUMBER() function in conjunction with the OVER clause to partition data. For instance, to divide a table into partitions of 100 rows each, you could use a query like this:
SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_num
FROM table_name;
Then, you can use the `row_num` column to select rows for each partition. For example, to select the first 100 rows (partition 1), you would use:
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (ORDER BY column_name) AS row_num
FROM table_name
) AS subquery
WHERE row_num BETWEEN 1 AND 100;
Example in Python
In Python, using the Pandas library, you can partition a dataframe into chunks based on row numbers. Here’s an example of how to do it:
import pandas as pd
# Assuming df is your dataframe
df = pd.DataFrame({
'column_name': range(1000) # Example data
})
# Define the chunk size
chunk_size = 100
# Loop through the dataframe in chunks
for i in range(0, len(df), chunk_size):
chunk = df.iloc[i:i + chunk_size]
# Process each chunk
print(chunk)
Key Points
- Row number partitioning is a technique used to divide datasets into manageable chunks based on row numbers.
- Applications include data sampling, parallel processing, and efficient data analysis.
- The choice of partitioning strategy (sequential, random, hash) depends on the application requirements.
- Implementation varies by database management system or programming language, with SQL and Python being common environments for such tasks.
- Libraries and functions like `ROW_NUMBER()` in SQL and Pandas in Python facilitate the partitioning process.
In conclusion, row number partitioning is a powerful technique for managing and analyzing large datasets. By understanding the different partitioning strategies and how to implement them in various environments, data analysts and programmers can efficiently process and gain insights from their data.
What is the primary purpose of row number partitioning?
+The primary purpose of row number partitioning is to divide large datasets into smaller, more manageable chunks, facilitating efficient data processing and analysis.
How do I choose the right partitioning strategy for my dataset?
+The choice of partitioning strategy depends on the nature of your data and the requirements of your application. Consider factors like data distribution, processing needs, and analysis goals when deciding between sequential, random, or hash partitioning.
Can I use row number partitioning for real-time data processing?
+Yes, row number partitioning can be used for real-time data processing, especially when combined with streaming data technologies and parallel processing frameworks. It helps in handling high volumes of data efficiently.