Apache Spark is a unified analytics engine for large-scale data processing, providing high-level APIs in Java, Python, Scala, and R. It offers various read options to load data from different sources, including files, databases, and messaging systems. Understanding these read options is crucial for efficiently processing and analyzing data in Spark applications.
Spark Read Options Overview

Spark supports multiple read options, allowing developers to choose the most suitable method based on their specific use case and data source. The primary read options in Spark include:
Key Points
- Text Files: Reading text files is one of the most basic read options in Spark, where data is loaded line by line.
- CSV Files: Spark can read comma-separated values (CSV) files, which are widely used for tabular data.
- JSON Files: JavaScript Object Notation (JSON) files can be read by Spark, offering a flexible data format for semi-structured data.
- Parquet Files: Parquet is a columnar storage format that allows for efficient data compression and encoding, making it a popular choice for big data analytics.
- Database Tables: Spark can read data from various database management systems, including relational databases and NoSQL databases.
Text Files Read Option
Reading text files in Spark is straightforward, where each line of the file is considered a separate record. This read option is useful for simple text data processing. Spark provides the textFile method to read text files, which returns an RDD (Resilient Distributed Dataset) containing the file’s content.
val textRDD = spark.sparkContext.textFile("path/to/text/file.txt")
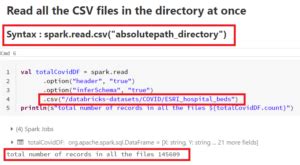
CSV Files Read Option
CSV (Comma Separated Values) files are widely used for tabular data, and Spark provides built-in support for reading CSV files using the read.csv method. This method returns a DataFrame, which is a distributed collection of data organized into named columns.
val csvDF = spark.read.csv("path/to/csv/file.csv")
JSON Files Read Option
JSON (JavaScript Object Notation) files can be read by Spark using the read.json method, which returns a DataFrame. JSON is a popular data format for semi-structured data, offering flexibility in data representation.
val jsonDF = spark.read.json("path/to/json/file.json")
Parquet Files Read Option
Parquet is a columnar storage format designed for efficient data compression and encoding. Spark supports reading Parquet files using the read.parquet method, which returns a DataFrame.
val parquetDF = spark.read.parquet("path/to/parquet/file.parquet")
Database Tables Read Option
Spark can read data from various database management systems, including relational databases and NoSQL databases. The read.format method is used to specify the database format, and the load method is used to load the data into a DataFrame.
val dbDF = spark.read.format("jdbc").option("url", "jdbc:postgresql://host:port/dbname").option("driver", "org.postgresql.Driver").option("dbtable", "tablename").option("user", "username").option("password", "password").load()
| Read Option | Description | Example |
|---|---|---|
| Text Files | Reading text files line by line | `textFile` method |
| CSV Files | Reading comma-separated values files | `read.csv` method |
| JSON Files | Reading JavaScript Object Notation files | `read.json` method |
| Parquet Files | Reading Parquet files for efficient data compression | `read.parquet` method |
| Database Tables | Reading data from various database management systems | `read.format` and `load` methods |

What is the most efficient way to read large text files in Spark?
+The most efficient way to read large text files in Spark is to use the `textFile` method with a partition size that matches the block size of the file system. This allows Spark to read the file in parallel, reducing the processing time.
How can I read a CSV file with a custom delimiter in Spark?
+To read a CSV file with a custom delimiter in Spark, you can use the `option` method to specify the delimiter. For example, `spark.read.option("delimiter", ";").csv("path/to/csv/file.csv")` reads a CSV file with a semicolon delimiter.
What is the difference between `read.csv` and `read.format("csv")` in Spark?
+`read.csv` and `read.format("csv")` are equivalent in Spark, both reading CSV files into a DataFrame. However, `read.format("csv")` provides more flexibility, allowing you to specify additional options, such as the delimiter and quote character.
Meta Description: Discover the various Spark read options for loading data from different sources, including files and databases, and learn how to choose the most suitable method for your use case. (150 characters)