Time series data has become increasingly important in various fields, including finance, IoT, and weather forecasting. As the volume and complexity of time series data continue to grow, the need for efficient and scalable databases to store and manage this data has become more pressing. In this article, we will explore five tips for choosing and implementing a time series database, highlighting key considerations and best practices for optimizing performance and reliability.
Key Points
- Understand the types of time series data and their storage requirements
- Choose a database that supports efficient data compression and querying
- Consider scalability and performance in handling high-volume data ingestion
- Ensure data retention and retrieval policies are in place for long-term data management
- Implement data visualization and analytics tools for actionable insights
Understanding Time Series Data and Storage Requirements

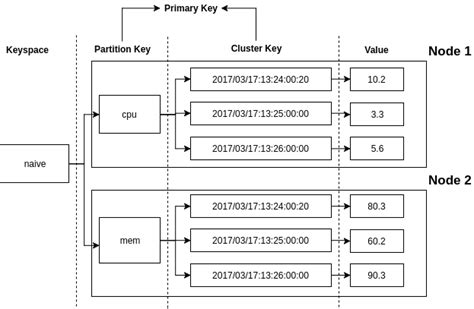
Time series data is characterized by a timestamp and a value, which can be a simple metric or a complex object. There are several types of time series data, including financial transactions, sensor readings, and log data. Each type of data has its own storage requirements, such as data frequency, retention period, and query patterns. For example, financial transactions may require high-frequency storage and rapid query performance, while sensor readings may require efficient data compression and aggregation.
When selecting a time series database, it is essential to consider the storage requirements of the data. Column-family databases like Cassandra and HBase are well-suited for storing large amounts of time series data, while relational databases like MySQL and PostgreSQL may be more suitable for smaller datasets with complex query patterns. Additionally, time series-specific databases like InfluxDB and OpenTSDB are designed to optimize storage and query performance for time series data.
Efficient Data Compression and Querying
Data compression is a critical aspect of time series data storage, as it can significantly reduce storage costs and improve query performance. Run-length encoding (RLE) and delta encoding are popular compression algorithms used in time series databases. When choosing a database, consider the compression algorithms supported and their impact on query performance.
Querying time series data can be complex, especially when dealing with large datasets. Aggregation functions like SUM, AVG, and MAX are commonly used to reduce data complexity, while filtering and grouping can help narrow down the data to specific time ranges or categories. Consider a database that supports efficient querying and aggregation, such as InfluxDB's Flux query language.
| Database | Compression Algorithm | Query Language |
|---|---|---|
| InfluxDB | RLE, Delta Encoding | Flux |
| OpenTSDB | Delta Encoding | TSDB Query Language |
| Cassandra | Snappy, LZ4 | CQL |

Scalability and Performance

Time series data can be generated at extremely high volumes, making scalability and performance critical considerations for a database. Distributed architectures like Cassandra and HBase can handle high-volume data ingestion and provide scalable storage, while in-memory databases like Redis and TimescaleDB can offer high-performance querying and aggregation.
When designing a time series database, consider the ingestion rate and query patterns of the data. A database that can handle high-volume ingestion and support efficient querying can help ensure reliable and performant data storage and retrieval.
Data Retention and Retrieval Policies
Data retention and retrieval policies are essential for long-term data management. Data retention periods can vary depending on the type of data and regulatory requirements, while data retrieval policies can help ensure that data is accessible and usable over time. Consider a database that supports flexible data retention and retrieval policies, such as InfluxDB’s data retention and data replay features.
Additionally, data backup and recovery are critical for ensuring data durability and availability. Consider a database that supports automated backup and recovery, such as Cassandra's snapshotting and repair features.
What is the difference between a time series database and a relational database?
+A time series database is optimized for storing and querying large amounts of time-stamped data, while a relational database is designed for storing and querying complex, structured data. Time series databases typically support efficient data compression, aggregation, and querying, while relational databases support complex query patterns and data relationships.
How do I choose the right time series database for my use case?
+Consider the type and volume of data, storage requirements, query patterns, and scalability needs. Evaluate databases based on their support for efficient data compression, querying, and aggregation, as well as their scalability, performance, and data retention and retrieval policies.
What are some best practices for implementing a time series database?
+Follow best practices such as designing a scalable and performant architecture, implementing efficient data compression and querying, and ensuring data retention and retrieval policies are in place. Additionally, consider implementing data visualization and analytics tools to provide actionable insights from the data.
In conclusion, selecting and implementing a time series database requires careful consideration of several factors, including storage requirements, query patterns, scalability, and performance. By understanding the types of time series data, choosing a database that supports efficient data compression and querying, and implementing best practices for data retention and retrieval, you can optimize your time series database for reliable and performant data storage and retrieval.